선행 내용
https://jooh3444.tistory.com/32
Two-pass Occlusion Culling
HZB Occlusion CullingHZB란? depth buffer의 Mipmap 이다.원본 depth buffer에서 downsampling을 해서 만들되, 상위 4 texel의 min / max 값을 가지고 있다.reversed-Z 여부에 따라 min/max 값 결정한다. (필요에 따라 둘 다 저
jooh3444.tistory.com
http://filmicworlds.com/blog/visibility-buffer-rendering-with-material-graphs/
Visibility Buffer Rendering with Material Graphs
filmicworlds.com
서론
UE5.6 을 기준으로 나나이트 동작을 분석해보자.
Nanite가 추구하는 최적화에 대한 내용은 이 글에서 다루지않고, 단순히 어떤식으로 GBuffer가 그려지는지 과정을 분석한다. 또한 큼지막한 패스만 분석하고 세세한 내용은 모드 생략한다. 사전지식으로 위의 Two pass Culling과 Visibility Buffer 관련 지식이 필요하다.
Nanite Overview
다양한 최적화 기법이 적용되어있지만, 기본적으로 Nanite Basepass의 기본 결과물은 Nanite Object들로부터 GBuffer 생성이다.
크게 Raster파트 / Shading 파트로 나눠서 분석해보자.
Raster 파트는 Nanite Object들로부터 VisibilityBuffer와 SceneDepth를 얻는 것이고
Shading 파트는 VisibilityBuffer와 SceneDepth, 그리고 이미 잘 만들어진 NaniteMaterial (GPU memory에 저장되어있음)을 활용하여 각 픽셀별 1회 Shading으로 GBuffer를 계산한다.
이 글에서 “이미 잘 만들어진” 이라는 말을 종종 사용할텐데, 나나이트가 워낙 볼륨이 커서, 복잡한 부분을 제거하고 Nanite Basepass의 Raster / Shading 쪽만 집중 분석하기 위해 다른 길로 샐 수 있는 부분은 적절히 생략한다.
Nanite Raster 파트
먼저 Culling 단위가 네 가지 있다.
HierarchyChunkCell, Instance, Node, Cluster (큰 순서대로)
- HierarchyChunkCell
- 월드를 그리드로 나눈 각 셀을 의미.
- Octree처럼 공간단위로 빠르게 컬링하기 위함.
- Instance
- Object단위. Object bounding box 사용
- Node
- 나나이트 메시에서 DAG구조에서의 Node 단위
- Node안에는 다수의 cluster가 있음.
- 고유의 bounding box를 가진다.
- 특수하게 NodeCulling패스에서는 Node의 streaming여부도 같이 처리한다. (나나이트 Virtualized Geometry)
- Cluster
- 삼각형 집합. Nanite Draw의 최소 단위.
- 역시나 고유의 bounding box를 가진다.
큰 순서대로 Culling을 진행한다. (Coarse To Fine)
먼저 HierarchyChunkCell을 진행하고, 그 다음 더 작은 단위인 Instance Cull, Node Cull, Cluster Cull을 진행한다.
이것이 한 패스이고,
Nanite는 Twopass Occlusion culling이므로 이를 두 번 시행한다. (Main, Post)
Culling
컬링은 위의 네 가지 패스에서 각각 진행되며, 거의 비슷한 로직으로 이루어진다.
각 단위는 고유의 bounding box를 가지는데, 그 bounding box를 기준으로 컬링한다.
- Distance Culling
- 해당 단위의 property를 적절히 참고해서 distance에 의한 컬링.
- 예) Actor property의 max distance 설정에 의한 컬링 등.
- Frustum Culling.
- view frustum 에 의한 컬링.
- HZB Culling.
- Hi-Z 버퍼를 사용한 Occlusion 컬링.
- MainPass에서는 PreviousHZB를 사용해서 컬링, PostPass에서는 CurrentHZB를 사용해 컬링
Persistent Culling
Default
일반적으로는 NodeCull_%d로 DAG Root로 부터 Depth가 0,1,2 …. 이런식으로 노드를 분류해놓고, Node %d에서 해당 depth 노드들을 일괄처리한다.
0번에서 visible하지만 streaming에 의해 load되지않았다고 표시된 Node는 child node들을 다음패스(NodeCull_1) 에 보내진다. 이를 반복 …
즉 Dispatch콜이 (n+1)개 생긴다.
- NodeCull_0 ~ NodeCull n
- Cluster Cull
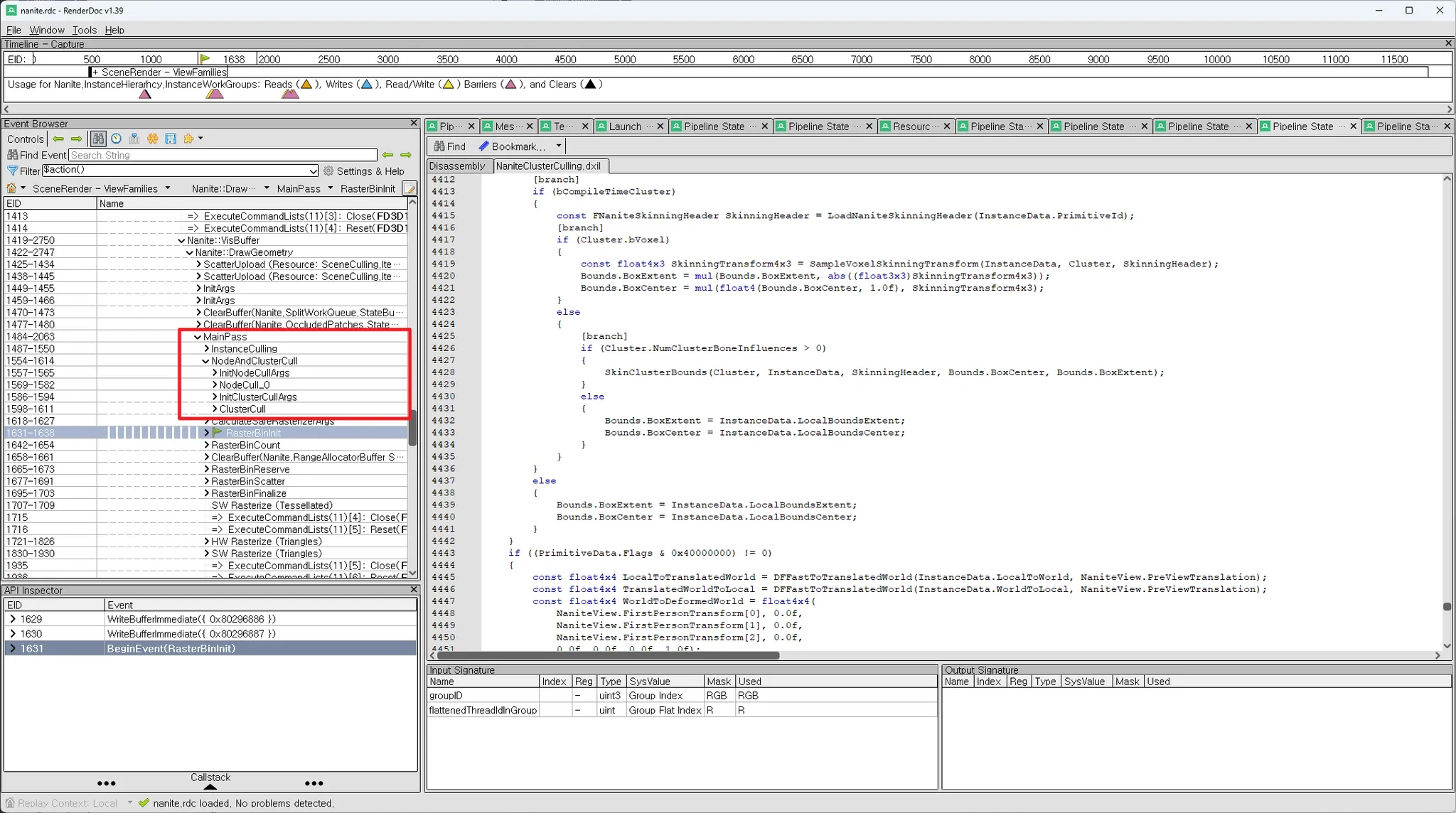
Persistent Culling
반면 Persistent Culling은 위의 (n+1)개의 동작을 하나의 dispatch에서 모두 해버린다. (노드 탐색을 반복문을 사용하여)
성능 테스트는 해봐야겠지만, 직관적으로는 depth가 여러 단계를 사용하는 경우 ( NodeCull_%d호출이 많을수록) Persisten Culling이 아닌 동작이 효율이 좋아보인다. (warp branch divergence 관련 지식 참고)
Two-Pass Culling
- MainPass에서는 PreviousHZB를 사용해서 컬링하여 draw하고, currentHZB도 만든다.
- PostPass에서는 MainPass에서 그리지않은 Cluster만 골라서 처리한다.
- 이 때 CurrentHZB를 사용해 컬링한다.
- 두 패스를 마치고나면 보이는 모든 cluster는 Draw 되었다고 볼 수 있다.
Raster Pass
보이는 모든 Cluster를 모으는데에 성공했다.
다음 단계는 이들을 Rasterize해서 Visibility Buffer에 PrimitiveId, TriangleId, Depth를 쓰는 것이다.
모든 Cluster를 하나의 파이프라인으로 래스터라이즈 가능한가?
⇒ 불가능하다.
이유는 머터리얼마다 vertex shader 및 pipeline의 동작이 다르기 때문이다.
예시로 two-sided material인 것과 아닌 머터리얼은 다른 raster_desc 의 culling_mode가 달라야하기 때문에 다른 파이프라인으로 그려주어야한다.
그래서 뒤에 언급할 Raster***패스들은 같이 묶어서 Draw할 Cluster들을 같은 RasterBin안에 넣는 분류작업을 하는 것이다.
RasterBinInit , RasterBinCount, RasterBinReserve, RasterBinScatter, RasterBinFinalize 이 그러하다.

간단한 테스트씬이어서 0번, 16번 Raster Bin에 각각 5개 4개의 HW raster 밖에 없지만 대략 이런식으로 분류가 된다.
이 RasterBin 분류 과정이 완료되면 이어질 HW Rasterize, SW Rasterize에서 사용할 IndirectDrawArgs들이 완성된다. C++ 단에도 RasterBin 정보가 있기 때문에 IndirectDrawInstance or IndirectDispatchMesh 콜을 얼마나 호출할지도 결정된다.
HW SW Rasterize
위에서 분류한 RasterBin, IndirectDrawArgs 정보를 바탕으로 Rasterize 실행한다.
목표는 Vis64Buffer 안에 (Cluster, TriangleIndex, Depth) 정보를 pack하여 저장해두는 것이다.
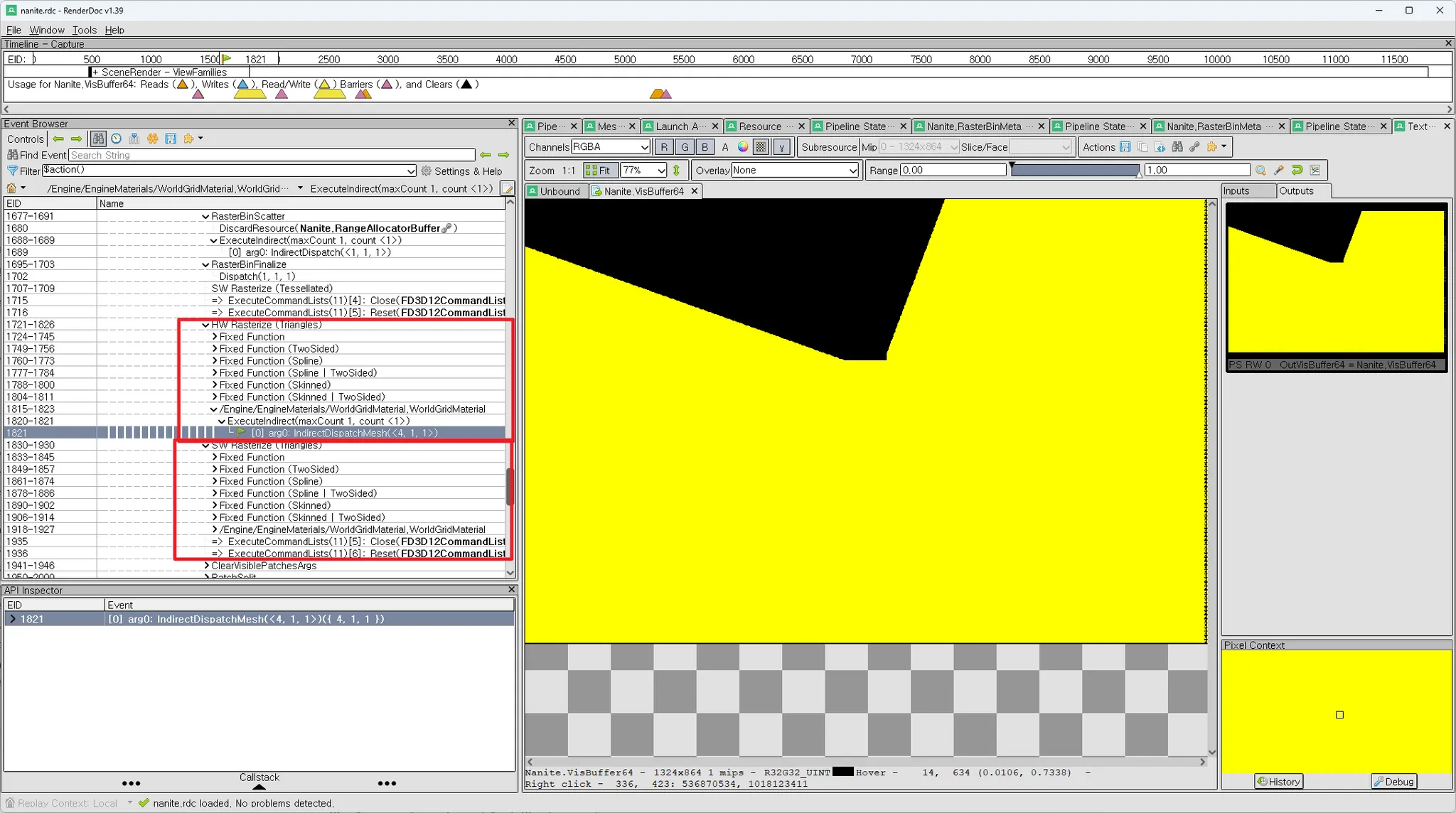
재밌는 점은 같은 MI를 사용하는 다른 인스턴스들이 같은 RasterBin에 들어가서 하나의 call로 draw를 완료해버린다.
SW Rasterize
Software Rasterize는 단어 그대로 Rasterize를 하드웨어 동작으로 하지않고, ComputeShader에서 직접 triangle 정보를 바탕으로 Rasterize 계산을 하는 방식이다.
삼각형이 매우 작은 경우가 아니라면, HW Rasterize가 대부분 빠르지만, 픽셀크기에 가까운 작은 삼각형의 경우 quad draw때문에 SW Rasterize가 이점을 가진다.
자세한 정보는 이 글에선 생략한다. 궁금하다면 아래 블로그 글 참고.
http://filmicworlds.com/blog/visibility-buffer-rendering-with-material-graphs/
Raster Part 요
다시 요약해보면
- Two-Pass컬링 + HierarchyCell ~ Cluster로 이어지는 Coarse To Find 컬링.
- RasterBin에 Draw 단위별로 Cluster분류. 한꺼번에 모으기
- RasterBin 개수만큼의 HW SW Rasterize 실행. Visibility Buffer 제작.
Raster파트 끝.

Nanite Shading 파트
Nanite::EmitDepthTargets
- Depth는 단순히 기준 SceneDepthZ 에다가 VisBuffer의 depth값을 덮으면 되고,
- Velocity는 이 셰이더에서 직접 계산한다. (FCluster객체로 부터 모든 InstanceData, PrimitiveData를 가져올 수 있다.)
float4 CalculateNaniteVelocity(FNaniteView NaniteView, FInstanceSceneData InstanceData, FCluster Cluster, FVisibleCluster VisibleCluster, float4 SvPosition, uint TriIndex, uint PrimitiveFlags, bool bWPOEnabled)
{
skinning data 및 dynamic instance data 로드해서 계산 ...
...
}
- Nanite.ShadingMask는 해당 픽셀의 ShadingBinID를 저장해두는 렌더타겟이다. 즉 어떤 Shading을 사용할지 결정. 이미 잘 만들어진 Scene_NaniteMaterials_MaterialData 에서 가져올 수 있다. (PrimitiveId, InstanceId, TriangleId, ShaderPass 를 key로 사용) 바로 다음패스인 EmitStencil에서 어떻게 사용하는지 볼 수 있다.
Nanite::EmitStencil
- Stencil은 Material 정보에서 bIsDecalReceiver 값이 필요해서 앞서 제작한 ShadingMask 렌더타겟을 사용한다. UnpackShadingMask(ShadingMaskId)를 통해 FShadingMask 접근을 하면 머터리얼의 속성을 가져올 수 있다.
- bIsDecalReceiver 인 경우에 SceneDepth에 스텐실을 덮어쓴다.
이제 SceneDepth / Stencil를 그리는 것은 완료.
ShadingMask 렌더타겟을 사용하여 Shading 계산을 진행 후 이를 GBuffer에 저장하는 일이 남아있다.
Nanite::Shading 파트에서 담당한다.
Nanite::ShadeBinning 파트
Shading Part의 목적은 Visibility Buffer로부터 GBuffer를 만드는 것이 목표이다.
가장 먼저 Binning 동작을 하는데, 이번에는 “Shade” Binning이다.
Bin에 분류하는 동작은 같으, 이번에는 Rasterize를 위해 분류가 아니라 Shading 을 위해 같은 요소들끼리 분류하는 것이다.
왜 분류할까?
이유는 같은 shading shader를 호출하는 픽셀끼리는 다같이 묶어서 계산하기 위함이다.
Static Mesh A와 Static Mesh B가 같은 동작의 셰이딩을 한다면, 두개가 그려진 픽셀은 묶어서 LightingCS 셰이더에 태워버리면 한번의 콜만으로 픽셀을 채울 수 있게 된다.

Binning을 위해 ShadingCount - ShadingReserve - Shading Scatter 패스를 순서대로 실행한다.
Nanite.ShadingBinData 구조
먼저 Shading Binning에서 가장 중요한 데이터 Nanite.ShadingBinData를 살펴보면
const uint32 NumBytes_Meta = sizeof(FNaniteShadingBinMeta) * ShadingBinCountPow2;
const uint32 NumBytes_Data = PixelCount * 8;
Binning.ShadingBinData = GraphBuilder.CreateBuffer(FRDGBufferDesc::CreateByteAddressDesc(NumBytes_Meta + NumBytes_Data), TEXT("Nanite.ShadingBinData"));
이런식으로 생겼는데, Bin0 ~ BinN^2 에는 FNaniteShadingBinMeta 정보가 저장,
Pixel에는 PackedShadingQuad 정보가 저장된다.
struct FNaniteShadingBinMeta
{
uint ElementCount; // 셰이딩할 Element개수
uint WrittenCount; // Element개수 다 채웠는지 체크하기 위함 (모든 패스 후에 ElementCount와 같아짐)
uint RangeStart; // PackedShadingQuad 정보를 얻기위한 offset
uint MaterialFlags; // 머터리얼 정보
};
uint2 PackShadingQuad(uint2 TopLeft, uint2 VRSShift, uint WriteMask)
{
uint2 Packed;
Packed.x = (VRSShift.y << 29) | (VRSShift.x << 28) | (TopLeft.y << 14) | TopLeft.x;
Packed.y = WriteMask;
return Packed;
// TopLeft : 픽셀 위치
// VRSShift, WriteMask : VRS관련 변수. 일단 무시
}
ShadingCount
Nanite.ShadingBinData 의 ElementCount를 계산하는 패스
MaterialFlags는 이미 잘 채워져있다.
ShadingReserve
위에서 언급한 PackedShadingQuad을 만들어서 넣어주고, 그것을 redirect해야하기 때문에
FNaniteShadingBinMeta의 RangeStart도 계산해서 채워준다.
이후 진행할 ShadeGBufferCS 에서 Material Instance당 하나의 IndirectDispatch를 호출하여 해당하는 모든 픽셀을 계산해주어야하는데, 이 IndirectDispatch호출을 위해 Nanite.ShadingBinArgs도 채워준다. Dispatch<픽셀개수, 1, 1>
ShadingScatter
struct FNaniteShadingBinScatterMeta
{
int RangeEnd;
int FullTileElementCount;
int LooseElementCount;
}
FNaniteShadingBinScatterMeta 는 Bin개수만큼 있으며,
ShadingScatter패스는 해당 메타데이터를 채워주는 역할을 하는데,
FullTile인지 Loose인지 결정을 하는데, Quad를 계산해야하면 FullTile 아니면 Loose인것같다.
사실 이 ScatterMetaData가 왜 필요한지는 잘 모르겠다.
ShadeGBufferCS
MI 개수만큼의 CS Dispatch를 실행.
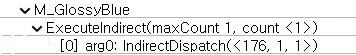
또한 Invoke 픽셀 갯수를 알아야하는데, 이는 ShadingBinArgs 에 채워져있다.
하나의 Dispatch만 했는데 아래처럼 instancing을 안해도 같은 material instance사용 메시가 한번에 묶여서 그려지는 것을 볼 수 있다.
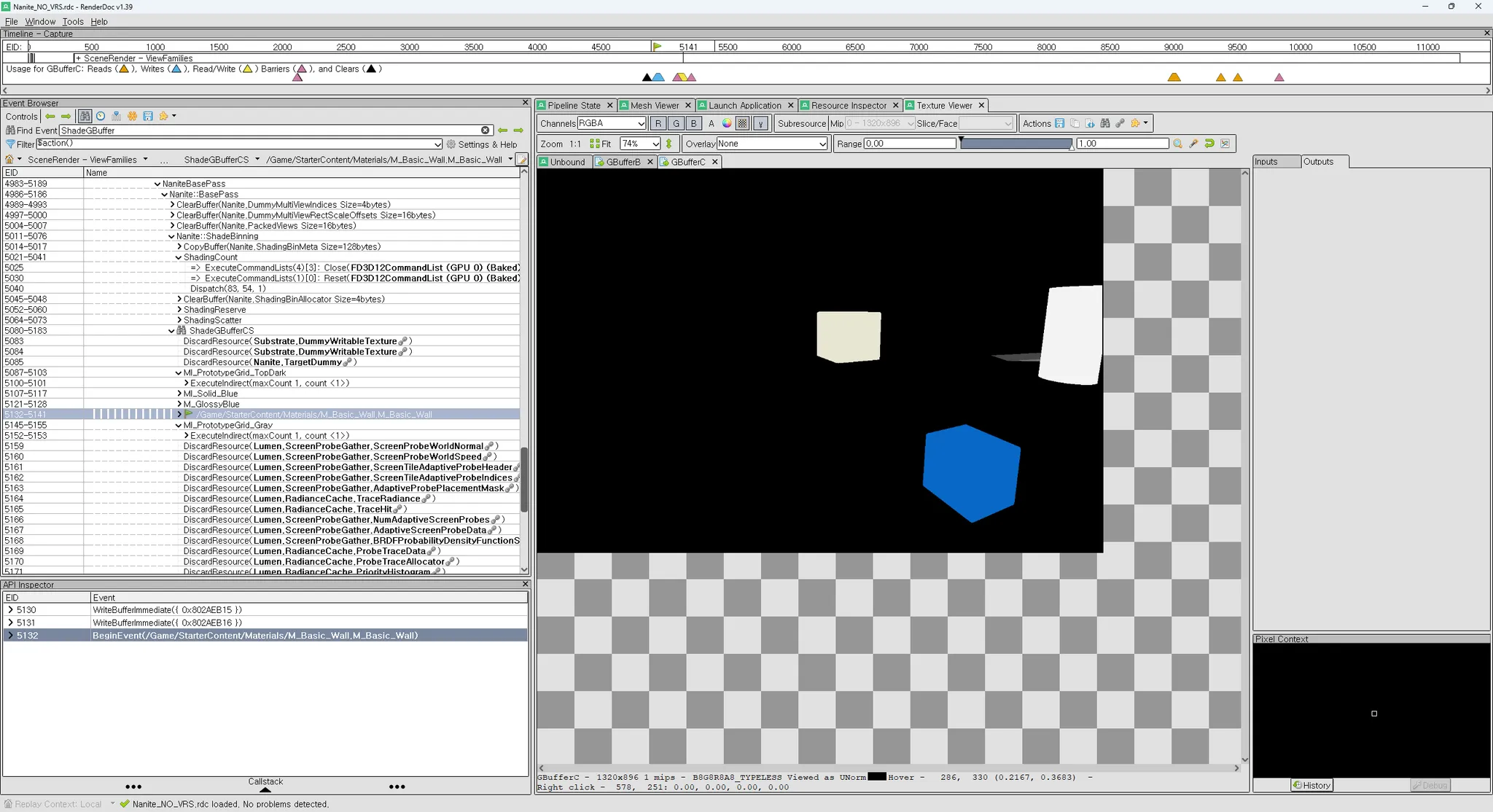

IndirectDispatch(<4334, 1, 1>) 로 4334 * 64 = 277376 의 픽셀이 한번에 그려졌다.
모든 ShadingBin 대상으로 IndirectDispatch를 실행해주고나면 GBuffer가 완성된다.
참고로 이렇게 CS로 픽셀별로 그리는 방식은 최적화의 일환으로, UE5.4 에 “Nanite Compute Material” 이라는 이름으로 추가되었다. 기존에는 Rasterize로 처리했다고 한다.
Shading 파트 끝
다시 한번 정리해보면, Nanite Raster 파트에서는 (PrimitiveId, TriangleId, Depth) 가 패킹된 렌더타겟을 만들어 냈다.
이를 간단히 제어하면 SceneDepth, Scene Stencil 를 만들어낼 수 있었다.
이후, Shading 파트에서는 같은 Shading을 사용하는 픽셀들에 대해서 한번의 Dispatch콜로 그려주기위해 먼저 ShadingBinning을 해서 분류한다.
ShadingCount - ShadingReserver - ShadingScatter 패스를 거쳐서 Nanite.ShadingBinData Nanite.ShadingBinArgs 데이터를 채워줄 수 있었고, 잘 정리된 데이터를 기반으로 모든 ShadingBin에 대해서 IndirectDispatch를 호출해주었다.
결과적으로 GBuffer를 모두 그릴 수 있다.
출처
- Visibility Buffer Rendering with Material Graphs
http://filmicworlds.com/blog/visibility-buffer-rendering-with-material-graphs/
- Unreal Engine 5.6
https://github.com/EpicGames/UnrealEngine
'언리얼 엔진' 카테고리의 다른 글
| [Unreal Engine 5] Virtual Shadow Map - 렌더패스 분석 (2) | 2025.08.21 |
|---|---|
| [Unreal Engine 5] Virtual Shadow Map (1) | 2025.07.29 |
| Expert's guide to unreal engine performance (0) | 2023.09.01 |
| UE5.1 Planar reflection과 VSM 동시 사용 시 프레임 드랍 문제 (0) | 2023.08.03 |
| [언리얼 엔진] Referencing Assets 쿠킹 테스트 (0) | 2023.03.24 |